Keyword [R-CNN]
Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
1. Overview
论文提出R-CNN模型 (combine region proposals with CNN),在VOC 2012物体检测任务上达到53.3% mAP,相对于当前best result提高了30%。
由于detection标注数量较少,而classification标注数量较多。因此
- 首先,基于classification标注信息预训练分类网络
- 接着,针对detection标注信息,选择合适的分类层替换分类网络中最后的分类层,进行微调
- 最终,利用该网络(去掉一些fc和softmax层)提取的4096维特征,训练SVM分类器

2. Modules
R-CNN模型包含3个模块: Region Proposal, CNN, SVM.
2.1. Region Proposals
- 选用selective search方法:
- 初始化n个region,组成region集合R
- 计算每两个region之间的相似度,加入相似度集合S中
- 选出S中相似度最大的region pair (r_{i}, r_{j}),将r_{i}, r_{j}合并为r_{t}
- 从S中剔除与r_{i}, r_{j}有关的region pair
- 计算r_{t}与剩余所有region的相似度,并加入S中
- 将r_{t}加入到R中
- 重复[加粗部分]直到S为空

2.2. Feature Extraction
- 输入为mean-subtracted 227*227 RGB,结构由5层CNN和2层FC组成,输出为4096维特征向量。对proposal进行transform的3种方法
- 将proposal放入tightest框中,并额外加入context信息
- 将proposal放入tightest框中,不加入context信息
- warp
- 此外,每种方法都是用context padding p像素

3. 测试阶段
- 使用selective search方法提取2000个region proposal.
- 最终用贪心non-maximum suppression算法reject proposal预测结果数量。
3.1. non-maximum suppression (NMS)
- 对于一个特定的分类
- 从region预测结果集合P中,选出最高得分的region A
- 遍历region集合,剔除与A的IoU大于指定阈值的region
- 将A存入最终目标结果集合Q中
- 重复上述3个步骤,直至P为空,则Q为最终所求的预测regions
- 对N个类别重复上述整个过程。
3.2. 测试耗时
13s/image on GPU, 53s/image on CPU. 主要耗时在于dot product和NMS。在实际中,将一个图像中的2000个proposal组成一个矩阵,因此Feature extraction输出的特征为2000*4096.
4. 训练阶段
训练分为3个阶段:监督预训练、微调、SVM分类器训练。
4.1. 监督预训练
使用auxiliary数据集(ILSVRC2012 classification)预训练分类网络。
4.2. Domain-specific fine-tuning
- 把分类网络的最后一层(1000 way)替换成随机初始化的(N+1背景 way)层。
- 正样本 与ground-truth的IoU≥0.5的region
- 负样本
- minibatch 128 (32正样本+96负样本)
4.3. SVM分类器
- 正样本 ground-truth
- 负样本 与ground-truth的IoU<0.3的region. 忽略>0.3的region
5. Bounding Box Regression
- 为了提高localization准确度,论文进一步在R-CNN模型中加入了bounding box regression. ground truth和每个proposal的bounding box都由坐标(中心点坐标,宽,高)表示
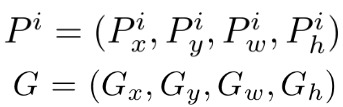
- 通过学习一个映射,将proposal box映射到ground truth box.
6. 实验结果
